2020.12.23
1. NVIDIA GPU Operator
- https://developer.nvidia.com/blog/nvidia-gpu-operator-simplifying-gpu-management-in-kubernetes/
- Simplifying GPU Management in Kubernetes
- To provision GPU worker nodes in a Kubernetes cluster, the following NVIDIA software components are required – the driver, container runtime, device plugin and monitoring. The GPU Operator simplifies both the initial deployment and management of the components by containerizing all the components and using standard Kubernetes APIs for automating and managing these components including versioning and upgrades.
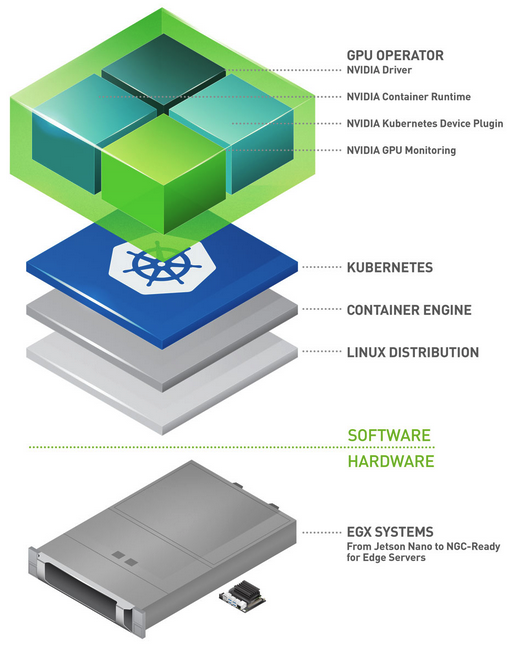
- The GPU operator should run on nodes that are equipped with GPUs. To determine which nodes have GPUs, the operator relies on Node Feature Discovery (NFD) within Kubernetes.
- The NFD worker detects various hardware features on the node – for example, PCIe device ids, kernel versions, memory and other attributes. It then advertises these features to Kubernetes using node labels. The GPU operator then uses these node labels to determine if NVIDIA software components should be provisioned on the node.
2. Environments
- Softwares
✓ CentOS 7.8, 3.10.0-1127.el7.x86_64, Kubernetes 1.16.15, Docker 19.03.13
✓ GPU Operator 1.4.0
NVIDIA Driver 450.80.02
CUDA 11.0
NVIDIA k8s device plugin 0.7.1
NVIDIA container toolkit 1.4.0
NVIDIA DCGM-exporter 2.0.13-2.1.2
Node Feature Discovery 0.6.0
GPU Feature Discovery 0.2.2
- GPU Card
✓ NVIDIA Tesla V100
3. Running the GPU Operator
a. Prerequisite
- https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/getting-started.html#prerequisites
- Nodes must not be pre-configured with NVIDIA components (driver, container runtime, device plugin).
- On node with GPU nodes
# lspci | grep -i nvidia
3b:00.0 3D controller: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] (rev a1)
d8:00.0 3D controller: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] (rev a1)
# modprobe -a i2c_core ipmi_msghandler
# lsmod | egrep "i2c_core|ipmi_msghandler"
ipmi_msghandler 56728 2 ipmi_ssif,ipmi_si
#
b. deploy the GPU operator
- https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/getting-started.html#install-helm
- https://github.com/NVIDIA/gpu-operator/tags
- https://developer.nvidia.com/blog/nvidia-gpu-operator-simplifying-gpu-management-in-kubernetes
$ helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
"nvidia" has been added to your repositories
$ helm repo update
Hang tight while we grab the latest from your chart repositories...
…
Successfully got an update from the "nvidia" chart repository
Update Complete. ⎈Happy Helming!⎈
$- https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/release-notes.html#id1
Due to a known limitation with the GPU Operator’s default values on CentOS, install the operator on CentOS 7/8:
This issue will be fixed in the next release (toolkit.version)
$ helm install nvidia/gpu-operator -n gpu-operator --generate-name --wait --version 1.4.0 --set toolkit.version=1.4.0-ubi8 # --dry-run > gpu-operator-1.4.0.yaml
NAME: gpu-operator-1606980427
LAST DEPLOYED: Thu Dec 3 16:27:09 2020
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None
$ helm list -n gpu-operator
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gpu-operator-1608268482 gpu-operator 1 2020-12-18 14:14:44.091117517 +0900 KST deployed gpu-operator-1.4.0 1.4.0
$ # helm pull nvidia/gpu-operator --create-namespace -n gpu-operator --generate-name --version 1.3.0 --untar
$
$ k get pod -n gpu-operator -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gpu-operator-1606963460-node-feature-discovery-master-6cb6p9db7 1/1 Running 0 2m51s 10.244.9.250 iap11 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-4792b 1/1 Running 0 2m50s 14.52.244.214 iap11 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-85d5v 1/1 Running 0 2m49s 14.52.244.208 iap04 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-h89rh 1/1 Running 0 2m49s 14.52.244.141 iap09 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-knr6c 1/1 Running 0 2m50s 14.52.244.140 iap08 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-ph5xv 1/1 Running 0 2m48s 14.52.244.213 iap10 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-vf42q 1/1 Running 0 2m51s 14.52.244.210 iap05 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-vxph8 1/1 Running 0 2m49s 14.52.244.211 iap06 <none> <none>
gpu-operator-1606963460-node-feature-discovery-worker-xz4w5 1/1 Running 0 2m49s 14.52.244.139 iap07 <none> <none>
gpu-operator-7659485bf7-fnljx 1/1 Running 0 2m51s 10.244.9.251 iap11 <none> <none>
$
- Troubleshooting
▷ Problem
$ k describe pod gpu-operator-b9fb68b4b-br7dt -n gpu-operator | grep Event -A10
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
…
Warning Failed 19s (x5 over 104s) kubelet, iap10 Error: failed to start container "gpu-operator": Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused "process_linux.go:449: container init caused \"process_linux.go:432: running prestart hook 0 caused \\\"error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: initialization error: driver error: failed to process request\\\\n\\\"\"": unknown
$▷ Solution
gpu-operator pod가 정상 기동시 daemon.json이 자동으로 생성 되었다가, POD 삭제시 daemon.json도 삭제 됨
nvidia-container-toolkit-daemonset-qsm9g에서도 유사 현상 발생되어 동일하게 조치 함
# cat /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
# rm /etc/docker/daemon.json
# systemctl restart docker
#- After a few minutes, the GPU operator would have deployed all the NVIDIA software components. The output also shows the validation containers run as part of the GPU operator state machine.
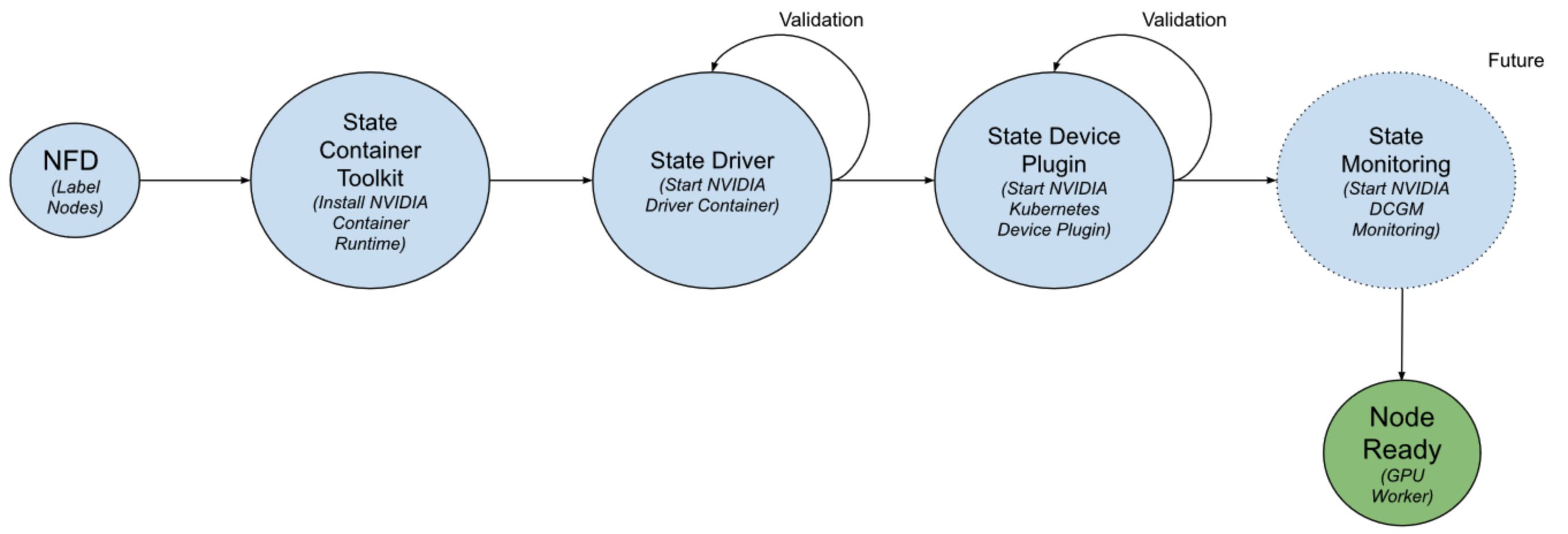
c. check NFD (Node Feature Discovery)
- NVIDIA GPU Feature Discovery for Kubernetes is a software component that allows you to automatically generate labels for the set of GPUs available on a node
- https://github.com/NVIDIA/gpu-feature-discovery
- GPU server에서 추가된 labels 정보
✓ GPU Operator v1.3.0, v1.4.0
feature.node.kubernetes.io/pci-0302_10de.present:true
nvidia.com/gpu.present:true
nvidia.com/gpu.product=Tesla-V100-PCIE-32GB
✓ GPU Operator v 1.2.0
feature.node.kubernetes.io/pci-10de.present:true
✓ PCI Vendor ID (10de) is NVIDIA Corporation
$ k get nodes iap10 -o jsonpath='{.metadata.labels}' | sed 's/ /\n/g' | grep pci
feature.node.kubernetes.io/pci-102b.present:true
feature.node.kubernetes.io/pci-10de.present:true
$ k get nodes iap11 -o jsonpath='{.metadata.labels}' | sed 's/ /\n/g' | grep pci
feature.node.kubernetes.io/pci-102b.present:true
feature.node.kubernetes.io/pci-10de.present:true
# V1.3.0, V1.4.0
$ k get nodes iap10 -o jsonpath='{.metadata.labels}' | sed 's/ /\n/g' | grep "gpu.present"
nvidia.com/gpu.present:true]
$
d. check NVIDIA GPU Driver
- The NVIDIA GPU driver container allows the provisioning of the NVIDIA driver through the use of containers. This provides a few benefits over a standard driver installation, for example:
✓ Ease of deployment
✓ Fast installation
✓ Reproducibility
- The driver container can be used in standard Linux distributions and container operating system distributions such as Red Hat CoreOS, Flatcar or other distributions. The driver container is also deployed as part of the NVIDIA GPU Operator.
- GPU Driver image release (https://ngc.nvidia.com/catalog/containers/nvidia:driver/tags)
✓ 450.80.02-centos7 : 12/05/2020
✓ 450.80.02-centos8 : 12/04/2020
✓ 450.80.02-rhel7.9 : 11/05/2020
✓ 450.80.02-1.0.1-rhel7: 10/29/2020
$ k edit daemonset.apps nvidia-driver-daemonset -n gpu-operator-resources
…
spec:
containers:
# Before
# - args:
# - init
# command:
# - nvidia-driver
- args:
- ln -s /lib/modules/3.10.0-1160.6.1.el7.x86_64 /lib/modules/3.10.0-1127.el7.x86_64 && nvidia-driver init
command:
- /bin/sh
- -c
…
$ k get pod -n gpu-operator-resources | egrep "NAME|nvidia-driver"
NAME READY STATUS RESTARTS AGE
nvidia-driver-daemonset-rfpgh 1/1 Running 162 2m
nvidia-driver-daemonset-rxwxk 1/1 Running 162 2m
nvidia-driver-validation 0/1 Completed 0 6s
$ k logs nvidia-driver-daemonset-rfpgh -n gpu-operator-resources
========== NVIDIA Software Installer ==========
Starting installation of NVIDIA driver version 450.80.02 for Linux kernel version 3.10.0-1127.el7.x86_64
…
Installation of the kernel module for the NVIDIA Accelerated Graphics Driver for Linux-x86_64 (version 450.80.02) is now complete.
Loading IPMI kernel module...
Loading NVIDIA driver kernel modules...
Starting NVIDIA persistence daemon...
Mounting NVIDIA driver rootfs...
Done, now waiting for signal
$ k logs nvidia-driver-validation -n gpu-operator-resources
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
$
- Troubleshooting #1
▷ Problem: "Could not resolve Linux kernel version"
GPU Operator v1.3.0, v1.4.0 동일 현상 발생
$ k logs nvidia-driver-daemonset-rxwxk -n gpu-operator-resources
========== NVIDIA Software Installer ==========
Starting installation of NVIDIA driver version 450.80.02 for Linux kernel version 3.10.0-1127.el7.x86_64
Stopping NVIDIA persistence daemon...
Unloading NVIDIA driver kernel modules...
Unmounting NVIDIA driver rootfs...
Checking NVIDIA driver packages...
Updating the package cache...
Unable to open the file '/lib/modules/3.10.0-1127.el7.x86_64/proc/version' (No such file or directory).Could not resolve Linux kernel version
Resolving Linux kernel version...
Stopping NVIDIA persistence daemon...
Unloading NVIDIA driver kernel modules...
Unmounting NVIDIA driver rootfs...
$▷ Cause
$ k exec nvidia-driver-daemonset-rxwxk -n gpu-operator-resources -it -- sh
sh-4.2# uname -r
3.10.0-1127.el7.x86_64
sh-4.2# ls /lib/modules/3.10.0-1127.el7.x86_64
ls: cannot access /lib/modules/3.10.0-1127.el7.x86_64: No such file or directory
sh-4.2# cat /lib/modules/3.10.0-1160.6.1.el7.x86_64/proc/version
Linux version 3.10.0-1160.6.1.el7.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) ) #1 SMP Tue Nov 17 13:59:11 UTC 2020
sh-4.2#▷ Solution
$ k edit daemonset.apps nvidia-driver-daemonset -n gpu-operator-resources
…
spec:
containers:
# Before
# - args:
# - init
# command:
# - nvidia-driver
- args:
- ln -s /lib/modules/3.10.0-1160.6.1.el7.x86_64 /lib/modules/3.10.0-1127.el7.x86_64 && nvidia-driver init
command:
- /bin/sh
- -c
…
$- Troubleshooting #2
▷ Problem:
GPU v1.3.0에서만 발생, GPU v1.4.0에서는 발생 되지 않음
$ k describe pod nvidia-driver-validation -n gpu-operator-resources | grep Events -A10
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned gpu-operator-resources/nvidia-driver-validation to iap10
Normal Pulled 10m (x5 over 11m) kubelet, iap10 Container image "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2" already present on machine
Normal Created 10m (x5 over 11m) kubelet, iap10 Created container cuda-vector-add
Warning Failed 10m (x5 over 11m) kubelet, iap10 Error: failed to start container "cuda-vector-add": Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused "process_linux.go:449: container init caused \"process_linux.go:432: running prestart hook 0 caused \\\"error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: ldcache error: open failed: /run/nvidia/driver/sbin/ldconfig.real: no such file or directory\\\\n\\\"\"": unknown
Warning BackOff 101s (x46 over 11m) kubelet, iap10 Back-off restarting failed container
$▷ Solution
# ln -s /run/nvidia/driver/sbin/ldconfig /run/nvidia/driver/sbin/ldconfig.real- Troubleshooting #3
▷ Problem:
$ k logs nvidia-driver-daemonset-rfpgh -n gpu-operator-resources
… Could not unload NVIDIA driver kernel modules, driver is in use
$▷ Cause: NVIDIA Driver가 OS에 이미 설치 되어 있기 떄문에 발생 됨
# lsmod | egrep "Module|nvidia"
Module Size Used by
nvidia_uvm 966382 0
nvidia_drm 48606 0
nvidia_modeset 1176938 1 nvidia_drm
nvidia 19636654 23 nvidia_modeset,nvidia_uvm
drm_kms_helper 186531 3 mgag200,nouveau,nvidia_drm
drm 456166 6 ttm,drm_kms_helper,mgag200,nouveau,nvidia_drm
#
## The third column in output is for ‘used by‘. It is basically used to display the number of instances of the module which are used.
# rpm -qa | grep nvidia | sort
libnvidia-container-tools-1.3.0-1.x86_64
libnvidia-container1-1.3.0-1.x86_64
nvidia-container-runtime-3.4.0-1.x86_64
nvidia-container-toolkit-1.3.0-2.x86_64
nvidia-docker2-2.5.0-1.noarch
# docker info | grep -i nvidia
Runtimes: nvidia runc
Default Runtime: nvidia
#▷ Solution
# yum remove nvidia-docker2 nvidia-container-runtime nvidia-container-toolkit
# cat /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
# rm /etc/docker/daemon.json
# systemctl restart docker
# docker info | grep -i nvidia
#
## How to Uninstall Manually Installed Nvidia Drivers in Linux (https://computingforgeeks.com/how-to-uninstall-manually-installed-nvidia-drivers-in-linux/)
# sh NVIDIA-Linux-x86_64-450.80.02.run --uninstall
Verifying archive integrity... OK
Uncompressing NVIDIA Accelerated Graphics Driver for Linux-x86_64 450.80.02...........
# systemctl restart kubelet
# lsmod | egrep "Module|nvidia"
Module Size Used by
#
e. Check nvidia-container-toolkit-daemonset
- The NVIDIA Container Toolkit allows users to build and run GPU accelerated containers. The toolkit includes a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs.
$ k get pod -n gpu-operator-resources | egrep "NAME|nvidia-container-toolkit-daemonset"
NAME READY STATUS RESTARTS AGE
nvidia-container-toolkit-daemonset-6pcqq 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-nfnxj 1/1 Running 0 14m
$ k logs nvidia-container-toolkit-daemonset-6pcqq -n gpu-operator-resources | egrep "^\["
[INFO] _init
[INFO] =================Starting the NVIDIA Container Toolkit=================
[INFO] toolkit::remove /usr/local/nvidia/toolkit
[INFO] toolkit::install
[INFO] toolkit::setup::config /usr/local/nvidia/toolkit
[INFO] toolkit::setup::cli_binary /usr/local/nvidia/toolkit
[INFO] toolkit::setup::toolkit_binary /usr/local/nvidia/toolkit
[INFO] toolkit::setup::runtime_binary /usr/local/nvidia/toolkit
[INFO] Refreshing the docker daemon configuration
[INFO] =================Done, Now Waiting for signal=================
$
## GPU Node
# ls -1 /usr/local/nvidia/toolkit/
-rwxr-xr-x 1 root root 166 5월 17 19:06 nvidia-container-runtime
-rwxr-xr-x 1 root root 195 5월 17 19:06 nvidia-container-toolkit
...
# cat /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"path": "/usr/local/nvidia/toolkit/nvidia-container-runtime"
}
},
"default-runtime": "nvidia"
}
#
# ps -ef | grep 2947 | head -n 1
root 2947 1 11 5월17 ? 1-13:17:49 /usr/bin/containerd
[root@iap10 toolkit]# ps -ef | grep 87639 | grep -v grep
root 87639 2947 0 5월25 ? 00:13:49 containerd-shim -namespace moby -workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/8c2ada4978993ba088244ad0372062be816c4937e8868dccfb7ef1230a013611 -address /run/containerd/containerd.sock -containerd-binary /usr/bin/containerd -runtime-root /var/run/docker/runtime-nvidia
# ps -ef | grep 132113 | grep -v grep
root 132113 87639 0 10:24 ? 00:00:00 /bin/sh /usr/local/nvidia/toolkit/nvidia-container-runtime --root /var/run/docker/runtime-nvidia/moby --log /run/containerd/io.containerd.runtime.v1.linux/moby/8c2ada4978993ba088244ad0372062be816c4937e8868dccfb7ef1230a013611/log.json --log-format json exec --process /tmp/runc-process237715488 --detach --pid-file /run/containerd/io.containerd.runtime.v1.linux/moby/8c2ada4978993ba088244ad0372062be816c4937e8868dccfb7ef1230a013611/3c86331cedd36dcf42180e63fab16c8622dab10bd056f11d7396da24edbf41a2.pid 8c2ada4978993ba088244ad0372062be816c4937e8868dccfb7ef1230a013611
# ps -ef | grep 132113 | grep -v grep
#
f. Check Device plugin
- The NVIDIA device plugin for Kubernetes is a DaemonSet that allows you to automatically
✓ Expose the number of GPUs on each nodes of your cluster
✓ Keep track of the health of your GPUs
✓ Run GPU enabled containers in your Kubernetes cluster.
$ k get pod -n gpu-operator-resources | egrep "NAME|nvidia-device-plugin"
NAME READY STATUS RESTARTS AGE
nvidia-device-plugin-daemonset-kq46z 1/1 Running 0 17m
nvidia-device-plugin-daemonset-qwfhf 1/1 Running 0 17m
nvidia-device-plugin-validation 0/1 Completed 0 9m40s
$ k describe nodes iap10
…
Capacity:
cpu: 80
…
nvidia.com/gpu: 2
…
$
g. Check dcgm-exporter
- DCGM-Exporter (https://github.com/NVIDIA/gpu-monitoring-tools)
- It exposes GPU metrics exporter for Prometheus leveraging NVIDIA DCGM.
$ k get pod -n gpu-operator-resources | egrep "NAME|nvidia-dcgm-exporter”
NAME READY STATUS RESTARTS AGE
nvidia-dcgm-exporter-426f4 1/1 Running 0 4d23h
nvidia-dcgm-exporter-wxkq6 1/1 Running 0 4d23h
$- Troubleshooting
▷ Problem #1
$ k describe pod nvidia-dcgm-exporter-56qjq -n gpu-operator-resources | grep Events -A15
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned gpu-operator-resources/nvidia-dcgm-exporter-56qjq to iap10
Warning Failed 4m21s kubelet, iap10 Error: failed to start container "nvidia-dcgm-exporter": Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused "process_linux.go:449: container init caused \"process_linux.go:432: running prestart hook 0 caused \\\"error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: mount error: file creation failed: /var/lib/docker/overlay2/f7a84d034eb655d20d188dc6d74e4d3e3c620ce1c66aae08257062f8f2cf8973/merged/dev/nvidia-uvm: no such device\\\\n\\\"\"": unknown
…▷ Problem #2
$ k logs nvidia-dcgm-exporter-cp4fm -n gpu-operator-resources
time="2020-12-16T06:22:43Z" level=info msg="Starting dcgm-exporter"
time="2020-12-16T06:22:43Z" level=info msg="DCGM successfully initialized!"
time="2020-12-16T06:22:43Z" level=fatal msg="Error watching fields: The third-party Profiling module returned an unrecoverable error"
$▷ Solution: GPU Operator v1.3.0에서 v1.4.0로 upgrade
4. Running Sample GPU Applications
a. CUDA FP16 Matrix multiply
$ cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: dcgmproftester
spec:
restartPolicy: OnFailure
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
args: ["--no-dcgm-validation", "-t 1004", "-d 120"]
resources:
limits:
nvidia.com/gpu: 1
EOF
$ k logs dcgmproftester -f
Skipping CreateDcgmGroups() since DCGM validation is disabled
CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_MULTIPROCESSOR: 2048
CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT: 80
CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 98304
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR: 7
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR: 0
CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH: 4096
CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE: 877000
Max Memory bandwidth: 898048000000 bytes (898.05 GiB)
CudaInit completed successfully.
Skipping WatchFields() since DCGM validation is disabled
TensorEngineActive: generated ???, dcgm 0.000 (72284.4 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (67266.7 gflops)
…
TensorEngineActive: generated ???, dcgm 0.000 (54648.1 gflops)
Skipping UnwatchFields() since DCGM validation is disabled
$ watch kubectl exec nvidia-driver-daemonset-kl4gp -n gpu-operator-resources -it -- nvidia-smi
Mon May 31 01:02:59 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... On | 00000000:3B:00.0 Off | 0 |
| N/A 55C P0 189W / 250W | 493MiB / 32510MiB | 65% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-PCIE... On | 00000000:D8:00.0 Off | 0 |
| N/A 26C P0 23W / 250W | 0MiB / 32510MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 16354 C /usr/bin/dcgmproftester11 489MiB |
+-----------------------------------------------------------------------------+
...
$ k exec dcgmproftester -it -- nvidia-smi
Mon May 31 01:05:00 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... On | 00000000:3B:00.0 Off | 0 |
| N/A 61C P0 188W / 250W | 493MiB / 32510MiB | 66% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
$
b. Jupyter Notebook
$ kubectl apply -f https://nvidia.github.io/gpu-operator/notebook-example.yml
service/tf-notebook created
pod/tf-notebook created
$ k get pod tf-notebook -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tf-notebook 1/1 Running 0 5m38s 10.244.10.132 iap10 <none> <none>
$ k get svc tf-notebook
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tf-notebook NodePort 10.111.206.73 <none> 80:30001/TCP 5m51s
$ k logs tf-notebook
[I 00:29:30.727 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
[I 00:29:30.918 NotebookApp] Serving notebooks from local directory: /tf
[I 00:29:30.918 NotebookApp] Jupyter Notebook 6.1.5 is running at:
[I 00:29:30.918 NotebookApp] http://tf-notebook:8888/?token=736793c504d7935ca45282bd40163bc4a1897ffec7509037
[I 00:29:30.918 NotebookApp] or http://127.0.0.1:8888/?token=736793c504d7935ca45282bd40163bc4a1897ffec7509037
[I 00:29:30.918 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 00:29:30.922 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-1-open.html
Or copy and paste one of these URLs:
http://tf-notebook:8888/?token=736793c504d7935ca45282bd40163bc4a1897ffec7509037
or http://127.0.0.1:8888/?token=736793c504d7935ca45282bd40163bc4a1897ffec7509037
[I 00:30:43.032 NotebookApp] 302 GET / (10.244.0.0) 1.57ms
[I 00:30:43.084 NotebookApp] 302 GET /tree? (10.244.0.0) 1.16ms
$- http://14.52.244.136:30001/?token=736793c504d7935ca45282bd40163bc4a1897ffec7509037

'Kubernetes > Install' 카테고리의 다른 글
| Kubernetes 업그레이드 (1.16 ⇢1.20) 및 호환성 검토 (0) | 2021.10.19 |
|---|---|
| GPU Operator Install on Ubuntu (0) | 2021.09.21 |
| Helm (0) | 2021.09.21 |
| MetalLB (0) | 2021.09.15 |
| keepalived, haproxy for K8s (0) | 2021.09.15 |



댓글