2021.02.24
1. Prometheus ?
- https://github.com/prometheus-operator/kube-prometheus
- kube-prometheus-stack
✓ Installs the kube-prometheus stack, a collection of Kubernetes manifests, Grafana dashboards, and Prometheus rules combined with documentation and scripts to provide easy to operate end-to-end Kubernetes cluster monitoring with Prometheus using the Prometheus Operator.
✓ Prometheus is deployed along with kube-state-metrics and node_exporter to expose cluster-level metrics for Kubernetes API objects and node-level metrics such as CPU utilization
- Prometheus (https://prometheus.io/)
✓ An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
✓ Prometheus's main features are:
▷ a multi-dimensional data model with time series data identified by metric name and key/value pairs
▷ PromQL, a flexible query language to leverage this dimensionality
▷ no reliance on distributed storage; single server nodes are autonomous
▷ ime series collection happens via a pull model over HTTP
▷ pushing time series is supported via an intermediary gateway
▷ targets are discovered via service discovery or static configuration
▷ multiple modes of graphing and dashboarding support
- Prometheus Architecture
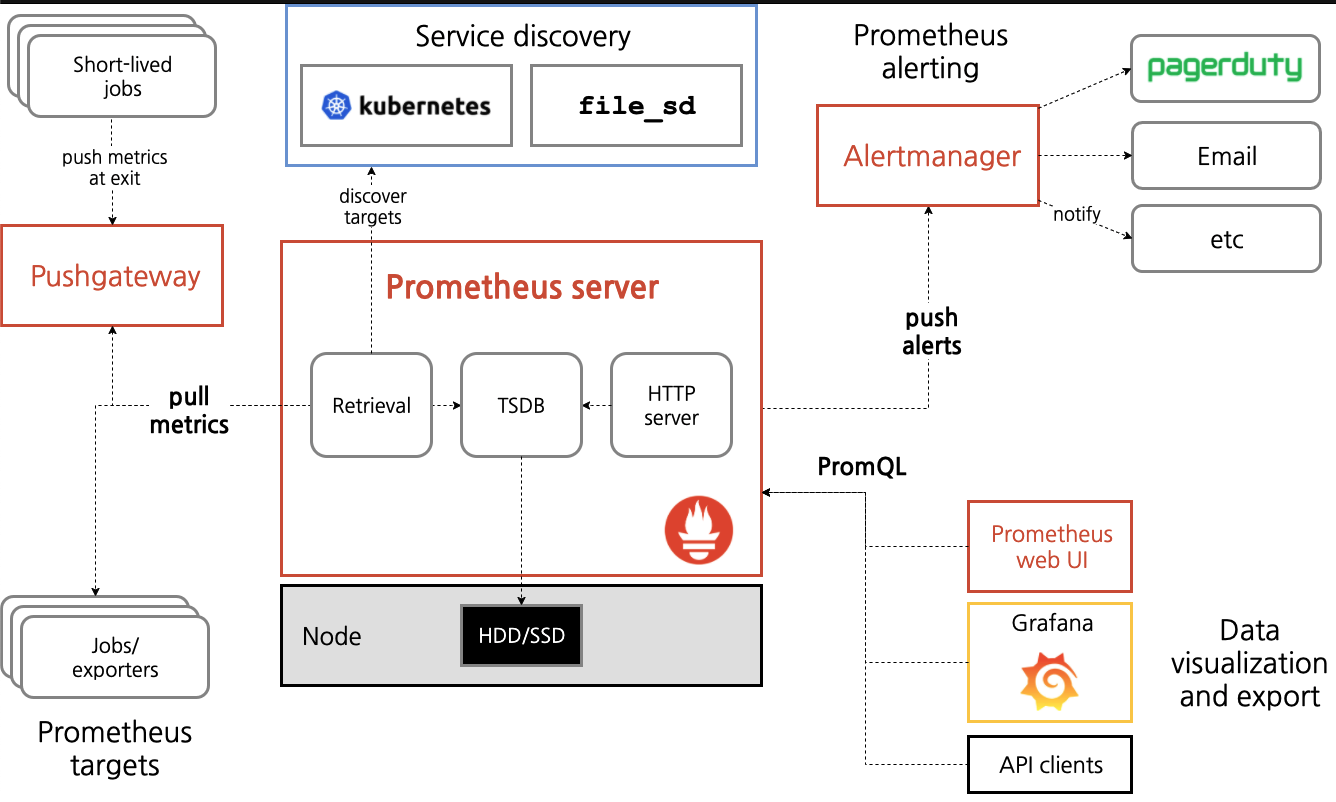
2. Environments
- Kubernetes 1.16.15
- kube-prometheus-stack 13.10.0
✓ prometheus operator 0.45.0
✓ grafana 7.4.1
✓ node-exporter v1.0.1
Prometheus exporter for hardware and OS metrics exposed by *NIX kernels, written in Go with pluggable metric
✓ kube-state-metrics v1.9.7
kube-state-metrics is a simple service that listens to the Kubernetes API server and generates metrics about the state
3. Metric 제공 소프트웨어
- GPU Operator v1.4.0) (NVIDIA DCGM-exporter 2.0.13-2.1.2) : It exposes GPU metrics exporter for Prometheus leveraging NVIDIA DCGM.
- RabbitMQ Cluster Operator 1.3.0 (annotation type)
- redis-cluster helm chart 4.2.5 (annotation type)
4. Install kube prometheus stack
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
$ helm repo update
…
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
$
$ helm inspect values prometheus-community/kube-prometheus-stack --version 13.10.0 > kube-prometheus-stack.values
$ vi kube-prometheus-stack.values
…
grafana:
adminPassword: prom-operator # default: prom-operator
…
prometheus:
service:
nodePort: 30090
type: NodePort # default: ClusterIP
…
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false # default: true
retention: 30d # default: 10d
…
storageSpec: {}
volumeClaimTemplate:
spec:
resources:
requests:
storage: 50Gi
…
additionalScrapeConfigs: []
#
# Prometheus can be configured to scrape all Pods with the prometheus.io/scrape: true annotation.
# Supported SW: RabbitMQ, Redis
# $ k describe pod aicc-server-0 -n rabbitmq-cluster | grep "prometheus.io"
# Annotations: prometheus.io/port: 15692
# prometheus.io/scrape: true
#
additionalScrapeConfigs:
- job_name: kubernetes-pods
honor_timestamps: true
scrape_interval: 30s # How frequently to scrape targets by default.
scrape_timeout: 30s # How long until a scrape request times out.
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
separator: ;
regex: ([^:]+)(?::\d+)?;(\d+)
target_label: __address__
replacement: $1:$2
action: replace
#
# Kubernetes SD configurations : endpoints (DCGM)
# Supported SW: DCGM(The NVIDIA Data Center GPU Manager)
#
- job_name: gpu-metrics
scrape_interval: 30s
scrape_timeout: 30s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- gpu-operator-resources
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
...
$ helm install prometheus-community/kube-prometheus-stack --create-namespace --namespace kube-prometheus-stack --generate-name \
--values kube-prometheus-stack.values
NAME: kube-prometheus-stack-1613969557
LAST DEPLOYED: Mon Feb 22 13:52:39 2021
NAMESPACE: kube-prometheus-stack
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace kube-prometheus-stack get pods -l "release=kube-prometheus-stack-1613969557"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
$ kubectl patch svc kube-prometheus-stack-1613969557-grafana -n kube-prometheus-stack -p '{ "spec": { "type": "NodePort" } }'
$
$ helm list -A | egrep 'NAME|prometheus'
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack-1613969557 kube-prometheus-stack 1 021-02-22 13:52:39 KST deployed kube-prometheus-stack-13.10.0 0.45.0
$ k get pod -n kube-prometheus-stack
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-1613-alertmanager-0 2/2 Running 0 9m48s
kube-prometheus-stack-1613-operator-5945548cd4-x7652 1/1 Running 0 9m50s
kube-prometheus-stack-1613969557-grafana-65ff6b7d5f-dbqvc 2/2 Running 0 9m50s
kube-prometheus-stack-1613969557-kube-state-metrics-754c984fshf 1/1 Running 0 9m50s
kube-prometheus-stack-1613969557-prometheus-node-exporter-vgszp 1/1 Running 0 9m50s
kube-prometheus-stack-1613969557-prometheus-node-exporter-vpb4b 1/1 Running 0 9m50s
kube-prometheus-stack-1613969557-prometheus-node-exporter-zhpn7 1/1 Running 0 9m50s
prometheus-kube-prometheus-stack-1613-prometheus-0 2/2 Running 1 9m48s
$ k get svc -n kube-prometheus-stack
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 9m55s
kube-prometheus-stack-1613-alertmanager ClusterIP 10.108.111.181 <none> 9093/TCP 9m59s
kube-prometheus-stack-1613-operator ClusterIP 10.101.15.13 <none> 443/TCP 9m59s
kube-prometheus-stack-1613-prometheus NodePort 10.96.39.250 <none> 9090:30090/TCP 9m59s
kube-prometheus-stack-1613969557-grafana ClusterIP 10.110.51.223 <none> 80/TCP 10m
kube-prometheus-stack-1613969557-kube-state-metrics ClusterIP 10.103.230.175 <none> 8080/TCP 9m59s
kube-prometheus-stack-1613969557-prometheus-node-exporter ClusterIP 10.97.101.160 <none> 9100/TCP 10m
prometheus-operated ClusterIP None <none> 9090/TCP 9m55s
$ k get pvc -n kube-prometheus-stack
NAME TATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-kube-prometheus-stack-1613-prometheus-... Bound pvc-260ff471-f742-45f6-b032-b2dd5282cd32 50Gi RWO nfs-sc-gmd 9m55s
$
5. Add scrape config
$ k get secrets kube-prometheus-stack-1613-prometheus-scrape-confg -n kube-prometheus-stack \
-o go-template='{{index .data "additional-scrape-configs.yaml" | base64decode }}' > additional-scrape-configs.yaml
$ vi additional-scrape-configs.yaml
...
# append new scrpe config below last line
- job_name: kubernetes-pods
scrape_interval: 30s
scrape_timeout: 30s
...
$ ADDITAIONAL_SCRAPE_CONFIG=$(base64 < "./additional-scrape-configs.yaml" | tr -d '\n')
$ kubectl patch secret kube-prometheus-stack-1613-prometheus-scrape-confg -n kube-prometheus-stack \
-p "{\"data\":{\"additional-scrape-configs.yaml\":\"${ADDITAIONAL_SCRAPE_CONFIG}\"}}"
$ k rollout restart statefulsets.apps prometheus-kube-prometheus-stack-1613-prometheus -n kube-prometheus-stack
$변경 내역은 Prometheus UI의 Status > configuration에서 확인 가능
6. Connect to Prometheus UI
- http://125.133.49.139:30090/
$ k get svc kube-prometheus-stack-1613-prometheus -n kube-prometheus-stack -o jsonpath='{.spec.ports[?(@.name=="web")].nodePort}'
30090
$
- Service Discovery : Menu - Status > Service Discovery

7. Import Dashboards to Grafana
- http://125.133.49.133:32200/
✓ username: admin
✓ password:
$ grep adminPassword kube-prometheus-stack.values
adminPassword: prom-operator
$
✓ Port:
$ k get svc kube-prometheus-stack-1613969557-grafana -n kube-prometheus-stack -o jsonpath='{.spec.ports[?(@.name=="service")].nodePort}'
32200
$
- Dashboard Import
+ > Import > Import via grafana.com > input “Dashboard ID”, load > import
- Dashboard ID 정보
✓ DCGM : 12239 (official), https://grafana.com/grafana/dashboards/12239
✓ RabbitMQ : 10991(official), https://grafana.com/grafana/dashboards/10991
✓ Redis : 11835(Non-official), https://grafana.com/grafana/dashboards/11835
12776(Official), https://grafana.com/grafana/dashboards/12776 - datasource : Prometheus 미지원
✓ Node : kube-prometheus-stack에서 다수의 dashbaord를 제공 (ex. Nodex, Kubernetes / Compute Resources / Node (Pods))
1860(Non-official), https://grafana.com/grafana/dashboards/1860

- Dashboards > Manage > Nodes > Mark as favorite
✓ Nodes
✓ Kubernetes / Compute Resources / Node (Pods)
8. Trouble shooting
a. Problem: podMonitor를 인식 하지 못 함
- https://www.rabbitmq.com/kubernetes/operator/operator-monitoring.html#prom-operator
- The Prometheus Operator defines scraping configuration through a more flexible custom resource called PodMonitor.
The PodMonitor custom resource definition (CRD) allows to declaratively define how a dynamic set of pods should be monitored.
The PodMonitor object introduced by the Prometheus Operator discovers these pods and generates the relevant configuration for the Prometheus server in order to monitor them.
- 테스트 환경
kube-prometheus-stack-12.10.6
prometheus-operator:v0.44.0
prometheus:v2.22.1
kubernetes 1.16.15, 1.17.14
$ vi rabbitmq-podmonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: rabbitmq
namespace: rabbitmq-monitor
spec:
podMetricsEndpoints:
- interval: 15s
port: prometheus
selector:
matchLabels:
app.kubernetes.io/component: rabbitmq
namespaceSelector:
any: true
$ k apply -f rabbitmq-podmonitor.yaml
podmonitor.monitoring.coreos.com/rabbitmq created
$b. Cause
- Prometheus UI > Status > Targets에서 podMonitor 관련 내용이 조회 되지 않음 …
- k8s 1.16.15, 1.17.14에서 logLevel=debug 변경 후
$ k logs -l app=kube-prometheus-stack-operator -n rabbitmq-monitor -f | grep -i monitors
level=debug ts=2021-01-07T11:49:12.248382883Z caller=operator.go:1631 component=prometheusoperator msg="filtering namespaces to select ServiceMonitors from" namespaces=rabbitmq-system,rabbitmq-cluster,rabbitmq-monitor,default,kube-node-lease,kube-public,kube-system namespace=rabbitmq-monitor prometheus=kube-prometheus-stack-1610-prometheus
level=debug ts=2021-01-07T11:49:12.25467112Z caller=operator.go:1692 component=prometheusoperator msg="selected ServiceMonitors" servicemonitors=rabbitmq-monitor/kube-prometheus-stack-1610-apiserver,rabbitmq-monitor/kube-prometheus-stack-1610-grafana,rabbitmq-monitor/kube-prometheus-stack-1610-kube-scheduler,rabbitmq-monitor/kube-prometheus-stack-1610-node-exporter,rabbitmq-monitor/kube-prometheus-stack-1610-kube-state-metrics,rabbitmq-monitor/kube-prometheus-stack-1610-operator,rabbitmq-monitor/kube-prometheus-stack-1610-coredns,rabbitmq-monitor/kube-prometheus-stack-1610-prometheus,rabbitmq-monitor/kube-prometheus-stack-1610-kubelet,rabbitmq-monitor/kube-prometheus-stack-1610-alertmanager,rabbitmq-monitor/kube-prometheus-stack-1610-kube-etcd,rabbitmq-monitor/kube-prometheus-stack-1610-kube-proxy,rabbitmq-monitor/kube-prometheus-stack-1610-kube-controller-manager namespace=rabbitmq-monitor prometheus=kube-prometheus-stack-1610-prometheus
level=debug ts=2021-01-07T11:49:12.254717786Z caller=operator.go:1727 component=prometheusoperator msg="filtering namespaces to select PodMonitors from" namespaces=rabbitmq-system,rabbitmq-cluster,rabbitmq-monitor,default,kube-node-lease,kube-public,kube-system namespace=rabbitmq-monitor prometheus=kube-prometheus-stack-1610-prometheus
level=debug ts=2021-01-07T11:49:12.254750262Z caller=operator.go:1780 component=prometheusoperator msg="selected PodMonitors" podmonitors= namespace=rabbitmq-monitor prometheus=kube-prometheus-stack-1610-prometheus- k8s 1.17.16
$ k logs -l app=kube-prometheus-stack-operator -n rabbitmq-monitor -f | grep -i podmonitor
…
level=debug ts=2021-01-08T01:06:29.318066557Z caller=operator.go:1727 component=prometheusoperator msg="filtering namespaces to select PodMonitors from" namespaces=kube-node-lease,default,rabbitmq-monitor,rabbitmq-system,rabbitmq-cluster,kube-system,kube-public namespace=rabbitmq-monitor prometheus=kube-prometheus-stack-1610-prometheus
level=debug ts=2021-01-08T01:06:29.318082198Z caller=operator.go:1780 component=prometheusoperator msg="selected PodMonitors" podmonitors= namespace=rabbitmq-monitor prometheus=kube-prometheus-stack-1610-prometheus
level=debug ts=2021-01-08T01:06:51.906724664Z caller=klog.go:55 component=k8s_client_runtime func=Verbose.Infof msg="pkg/mod/k8s.io/client-go@v0.19.2/tools/cache/reflector.go:156: Watch close - *v1.PodMonitor total 2 items received"
level=debug ts=2021-01-08T01:06:51.908978768Z caller=klog.go:72 component=k8s_client_runtime func=Infof msg="GET https://10.96.0.1:443/apis/monitoring.coreos.com/v1/podmonitors? allowWatchBookmarks=true&resourceVersion=1102&timeout=7m51s&timeoutSeconds=471&watch=true 200 OK in 2 milliseconds"
…
c. Workaround: podMonitor 대신 Scraping Annotations 설정으로 해결
'Kubernetes > Monitoring' 카테고리의 다른 글
| GPU Monitor (0) | 2021.09.21 |
|---|---|
| Elastic Observability (0) | 2021.09.20 |
| Elastic Observability - filebeat/metricbeat POD 오류 (0) | 2021.09.15 |
| Dashboard on bare-metal (0) | 2021.09.15 |
| Dashboard on GCE (0) | 2021.09.15 |



댓글